Ett Verkle-träd är ett åtagandesystem som fungerar på samma sätt som ett Merkle-träd, men som har mycket mindre vittnen. Det fungerar genom att ersätta hasharna i ett Merkle-träd med ett vektorengagemang, vilket gör bredare förgreningsfaktorer mer effektiva.
Tack till Kevaundray Wedderburn för feedback på inlägget.
För detaljer om hur verkle-träd fungerar, se:
Syftet med detta inlägg är att förklara den konkreta layouten av utkastet till verkleträdet EIP. Den riktar sig till klientutvecklare som vill implementera verkle trees och letar efter en introduktion innan de går djupare in i EIP.
Verkle-träd introducerar ett antal förändringar i trädstrukturen. De viktigaste förändringarna är:
Som vektorförpliktelseschema för verkleträdet använder vi Pedersen-åtaganden . Pedersens åtaganden baseras på elliptiska kurvor. För en introduktion till Pedersen-åtaganden och hur man använder dem som polynom- eller vektoråtaganden med hjälp av Inner Product Argumentss, se här.
Kurvan vi använder är Bandersnatch. Denna kurva valdes för att den är prestanda, och även för att den kommer att tillåta effektiva SNARKs i BLS12_381 att resonera om verkle-trädet i framtiden. Detta kan vara användbart för rollups samt tillåta en uppgradering där alla vittnen kan komprimeras till ett SNARK när det blir praktiskt, utan att behöva en ytterligare uppdatering av åtaganden.
Kurvordningen/skalärfältets storlek för bandersnatch är p =1310896879378154761986193512704649145930915589344057025178640330672906817628> , vilket är ett 253-bitars primtal. Som ett resultat av detta kan vi bara säkert binda till bitsträngar på högst 252 bitar, annars svämmar fältet över. Vi valde en förgreningsfaktor (bredd) på 256 för verkleträdet, vilket innebär att varje åtagande kan binda till upp till 256 värden på 252 bitar vardera (eller för att vara exakt, heltal upp till p - 1 ). Vi skriver detta som Commit(v₀, v₁, …, v₂₅₅) att förbinda sig till listan v av längden 256.
Ett av designmålen med verkle-trädet EIP är att göra åtkomst till närliggande positioner (t.ex. lagring med nästan samma adress eller angränsande kodbitar) billiga att komma åt. För att göra detta består en nyckel av en stam på 31 byte och ett suffix på en byte för totalt 32 byte. Nyckelschemat är utformat så att "nära" lagringsplatser mappas till samma stam och ett annat suffix. Mer information finns i EIP-utkastet.
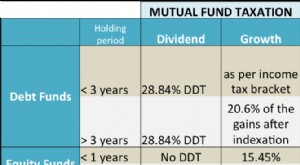
Verkleträdet i sig är då sammansatt av två typer av noder:
Engagemanget för en förlängningsnod är ett engagemang för en vektor med fyra element; de återstående positionerna kommer att vara 0. Det är:

C₁ och C₂ är ytterligare två åtaganden som förbinder sig till alla värden med stam lika med stam . Anledningen till att vi behöver åtaganden är att värden har 32 byte, men vi kan bara lagra 252 bitar per fältelement. Ett enda åtagande skulle alltså inte räcka för att lagra 256 värden. Så istället lagrar C₁ värdena för suffixet 0 till 127, och C₂ lagrar 128 till 255, där värdena delas i två för att passa in i fältstorleken (vi kommer till det senare.)
Förlängningen tillsammans med åtagandena C₁ och C₂ kallas för "extension-and-suffix tree" (förkortat EaS).
 Figur 1 Representation av en promenad genom ett verkleträd för nyckeln
Figur 1 Representation av en promenad genom ett verkleträd för nyckeln 0xfe0002abcd..ff04 :sökvägen går genom 3 interna noder med 256 barn vardera (254, 0, 2), en förlängningsnod som representerar abcd..ff och de två åtagandena för suffixträdet, inklusive värdet för 04 , v4. Observera att stam är faktiskt de första 31 byten av nyckeln, inklusive sökvägen genom de interna noderna.
Varje förlängnings- och suffixträdnod innehåller 256 värden. Eftersom ett värde är 256 bitar brett och vi bara kan lagra 252 bitar säkert i ett fältelement, skulle fyra bitar gå förlorade om vi helt enkelt försökte lagra ett värde i ett fältelement.
För att kringgå detta problem valde vi att dela upp gruppen med 256 värden i två grupper med 128 värden vardera. Varje 32-byte-värde i en grupp delas upp i två 16-byte-värden. Så ett värde V8 𝔹3 ^ omvandlas till v8 ∈ ^6 och v8 𝔹6, så att v⁽ˡᵒʷᵉʳ⁾ᵢ ++ v⁽ᵘᵖᵖᵉʳ⁾ᵢ =vᵢ.
En "lövmarkör" läggs till i v⁽ˡᵒʷᵉʳ⁾ᵢ, för att skilja mellan ett blad som aldrig har nåtts och ett blad som har skrivits över med nollor. Inget värde tas någonsin bort från ett verkleträd . Detta behövs för kommande statliga upphörande system. Den markören är inställd på 129:e biten, dvs v⁽ˡᵒʷᵉʳ ᵐᵒᵈⁱᶠⁱᵉᵈ⁾ᵢ =v⁽ˡᵒʷᵉʳ⁾ᵢ + 2 ^ ⁸ om vᵢ har nås tidigare, och v⁽ˡᵒʷᵉʳ ᵐᵒᵈⁱᶠⁱᵉᵈ⁾ᵢ =0 om vᵢ aldrig har nås.
De två åtagandena C₁ och C₂ definieras då som

Engagemanget för en förlängningsnod består av en "förlängningsmarkör", som bara är siffran 1, de två underträdsförpliktelserna C₁ och C₂ och stammen av nyckeln som leder till denna förlängningsnod.
Till skillnad från förlängningsnoder i Merkle-Patricia-trädet, som bara innehåller den sektion av nyckeln som överbryggar den interna modernoden till den underordnade interna noden, täcker stammen hela nyckeln fram till den punkten. Detta beror på att verkle-träd är designade med tillståndslösa bevis i åtanke:om en ny nyckel sätts in som "delar" förlängningen i två delar behöver inte det äldre syskonet uppdateras, vilket möjliggör ett mindre bevis.
Interna noder har den enklare beräkningsmetoden för sina åtaganden:noden ses som en vektor av 256 värden, som är (fältrepresentationen av) rotförpliktelsen för vart och ett av deras 256 underträd. Åtagandet för ett tomt underträd är 0. Om underträdet inte är tomt, är åtagandet för den interna noden

där Cᵢ är barn till den interna noden och 0 om ett barn är tomt.
Figur 2 är en illustration av processen att infoga ett nytt värde i trädet, vilket blir intressant när stjälkarna kolliderar på flera initiala bytes.
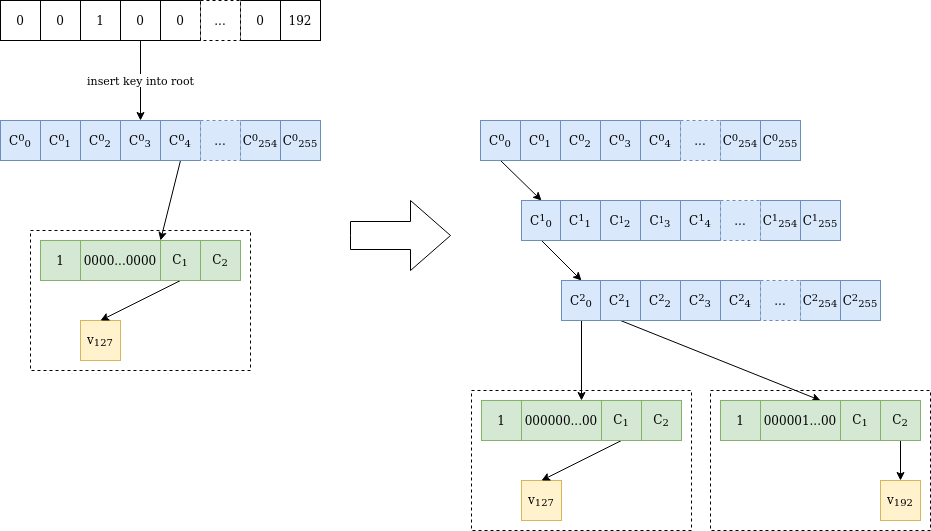
Figur 2 Värde v₁₉₂ har infogats på plats 0000010000...0000 i ett verkleträd som endast innehåller värdet v₁₂₇ på plats 0000000000...0000 . Eftersom stammarna skiljer sig åt vid den tredje byten, läggs två interna noder till tills den olika byten. Sedan infogas ett annat "extension-and-suffix"-träd, med en hel 31-byte stam. Den initiala noden är orörd och C²₀ har samma värde som C⁰₀ före infogningen.
Verkle-trädstrukturen ger grundare träd, vilket minskar mängden lagrad data. Dess verkliga kraft kommer dock från förmågan att producera mindre bevis, d.v.s. vittnen. Detta kommer att förklaras i nästa artikel.