Finansvärlden är behäftad med en sjukdom som är så utbredd och allmänt förekommande att inte ens "experter" verkar ta den på allvar som krävs. Sjukdomen, som inte visar några tecken på tillbakadragande när som helst snart, kallas "Data Mining". Här är hur det påverkar indexkonstruktionen och varför vi måste vara försiktiga. Detta är ett gästinlägg av en expert på finansmarknaderna som vill vara anonym av personliga skäl.
Många av läsarna som kommer från 'Tech'-bakgrund har alltid en positiv åsikt om datautvinning och med rätta eftersom data- och datautvinning har gjort underverk inom flera områden – från så enkla saker som att förstå kundernas beteende för att öka försäljningen till att analysera vädertrender att prognostisera – data- och datautvinning har varit så bra. Men i samband med finans- och investeringsförvaltning är "Data Mining" en pest.
I samband med finans/investeringsförvaltning, låt mig definiera vad är datautvinning? Data Mining är inget annat än att titta på tidigare data utan några ekonomiska och intuitiva skäl utan att leta efter mönster i synnerhet "överlägsen" prestanda. Med tanke på tillväxten i datorkraft och storskalig tillgänglighet av intradagsdata är det inte särskilt svårt för en halvanständig programmerare att skriva enkla skript för att komma med tusentals om inte miljontals backtests för att komma med fantastiska resultat. Men både proffs och investerare glömmer bekvämt bort den mest centrala grundsatsen i investeringar – "Det förflutna är inte en indikation på framtiden" trots att detta uttalande kastats bort av alla som någonsin har köpt en enskild aktie eller andel i en aktiefond.
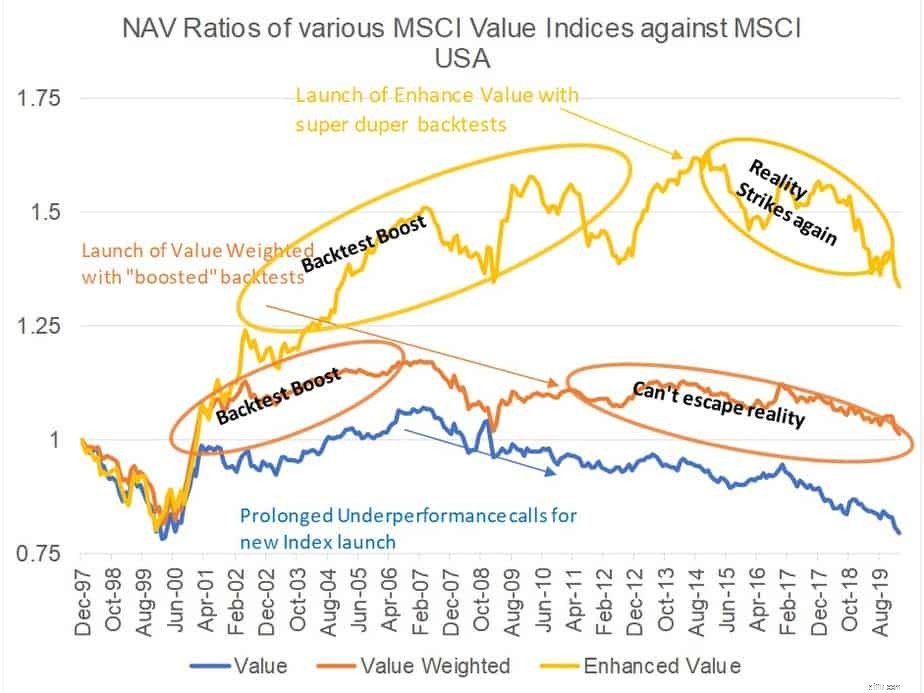
Här är en illustration av datautvinning i aktion. MSCI, världens största indexleverantör - med biljoner dollar som antingen spårar sina index eller jämförs med sina index, har tre olika "Value"-index – MSCI Value Index, MSCI Value Weed Index, MSCI "Enhanced" Value index. Vilken logisk person som helst skulle ställa följande frågor:Varför finns det tre olika värdeindex från samma leverantör? Vilken ska jag investera i? Vad är skillnaderna mellan dem? Hur är det ena bättre än det andra? MSCI Value den äldsta medlemmen i familjen har varit live sedan 1997, det värdevägda indexet lanserades i december 2010 och Enhanced Value i april 2015. Naturligtvis överträffar de nylanserade indexen de gamla indexen i backtests och det är "förbättringarna" ”.
Följande bild plottar NAV-kvoten för alla de tre värdeindexen mot det breda marknadsindexet. NAV-kvot, för dem som inte vet, är bara förhållandet mellan ett index NAV dividerat med ett annat index NAV. Den ekonomiska tolkningen av förhållandet är prestanda för en lång-kort portfölj där vi går "lång" på täljarindex/portfölj och "kort" på nämnarindex/portfölj. Så, om NAV-kvoten går upp, överträffar täljarindexet nämnarindexet (riktmärket i det här fallet) och när det går ner, presterar täljarindexet sämre än nämnaren. Som du kan se överträffar de senaste indexen de gamla med en betydande marginal, särskilt i backtests. Det är också intressant att se att nya index lanseras efter en långvarig dålig utveckling av sina föregångare. Det krävs inte ett team av rättsmedicinska analytiker och undersökande journalister för att få ihop 2+3=5. När indexen väl har lanserats och de går live, vad hände med dem? Det är resultatet av datautvinning. Icke-robusta backtests som plågas av datautvinning kommer förr eller senare att avslöja sin sanna färg. Faktum är att den akademiska värdefaktorn har underpresterat i mer än ett decennium. Ingen mängd datautvinning kan ändra det faktum. Hur vi än ser på värde så går det inte att undgå det. Det är dock en fantastisk tidigare prestation som säljer. En kille måste äta, och för att äta måste han sälja, så ..!
Man kan undra hur vi är så säkra på att det finns datautvinning? Varför kan vi inte ge dem fördelen av tvivel? Jo, det står i det fria i deras metoddokument. Följande är ett utdrag om hur MSCI väljer flera variabler och deras vikt vid konstruktionen av dess faktorer. De erkänner tydligt att de övervikter variabler som har visat bättre avkastning/volatilitet i backtests. Det är lärobokens definition av datautvinning och de säger öppet - de gör datautvinning. Det kan bara betyda en av två saker – 1. De vet inte ens att de gör datautvinning. 2. De bryr sig helt enkelt inte. Jag vet inte vilken av de två anledningarna som är farligare än den andra.
Det här är en skärmdump från sidan 8 i MSCI FaCS metoddokument

Texten återges nedan för tydlighetens skull:
Läsare kommer att fråga, detta är amerikanska data, amerikanska index, amerikanska leverantörer – jag investerar helt enkelt i fonder i Indien, varför skulle jag bry mig? Om problemet är detta uppenbart förekommande i index, vars tidigare testresultat, konstruktionsmetodik, lanseringsdatum och live track record är offentliga, föreställ dig omfattningen och storleken på dina aktiva favoritfonder som du inte har tillgång till någonting för. Det finns noll transparens. Index är regelbaserade och systematiska medan aktiva fonder är helt diskretionära. Jag kan omöjligt förstå i vilken skala datautvinning skulle vara utbredd i fondbranschen. Tack och lov kom SEBI med reglerna för att begränsa antalet fonder i varje kategori.
Detta är inte att säga att vi aldrig ska backtesta något eller aldrig titta på backtestprestanda. Självklart inte. Tidigare data är den enda information som är tillgänglig för oss för att fatta beslut. Vi borde ta det med en nypa salt. Som Pattu sir säger, "Cherry väljer bästa tidigare avkastning är fel. Att plocka körsbär värsta tidigare risken är försiktighet”. Det är ganska mycket det. En sammanfattning på en rad av vad datamining är och inte är. Det är så vi som investerare bör behandla backtests eller tidigare data i allmänhet – för att förstå risker. När det gäller branschen – det finns inget hopp.